一次有趣的尝试
前言#
众所周知,微信聊天数据库是加密的,但并不是无法解密。
目前主流的获取微信聊天记录的方法是用已 ROOT 的手机提取,;第二种为通过 Apple iTunes 备份(非加密,非侵入式备份然后获取)。
这里所说的两种办法网上都有很多文章,感兴趣的读者可以搜索看,我不在累叙这个过程,此文章主要说明一种侵入式的,PC 客户端可以做到的方法。
过程:#
微信聊天记录存储在数据库中,格式为 sqlite,也就是后缀为 DB。
但是加密了,所以需要先获取到解密密钥。解密密钥的获取一般都是在内存中,所以需要微信在登录状态下才能获取到。
解密数据库:#
微信数据默认情况下位于 C:\Users\xxx\Documents\WeChat Files\,而聊天记录数据库位于该目录下面的 wxid_xxxx\Msg\Multi。聊天记录文件命名一般是 MSG.db,超出 240MB 会自动生成 MSG1.db,以此类推
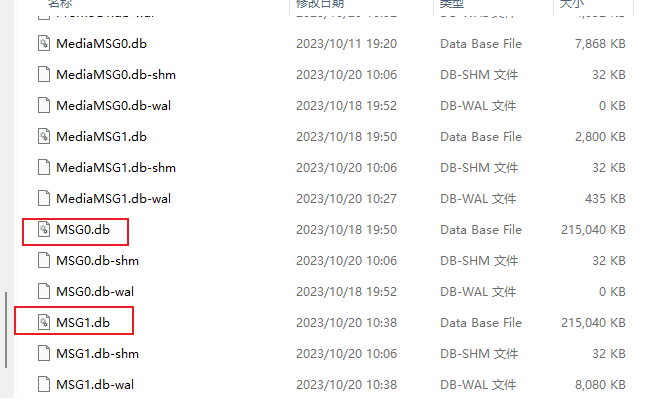
参考 GitHub 脚本利用:https://github.com/0xlane/wechat-dump-rs
目前我的微信版本是 3.9.7.25,到这个版本都是可以解密的,作者更新的基址也同样有效。
执行 - a 之后应该会在 temp 目录生成一个不加密的 MSG.db 文件。
可以用 navicat 之类的打开。
聊天记录部分是存在与 MSG 表里,大概如下:
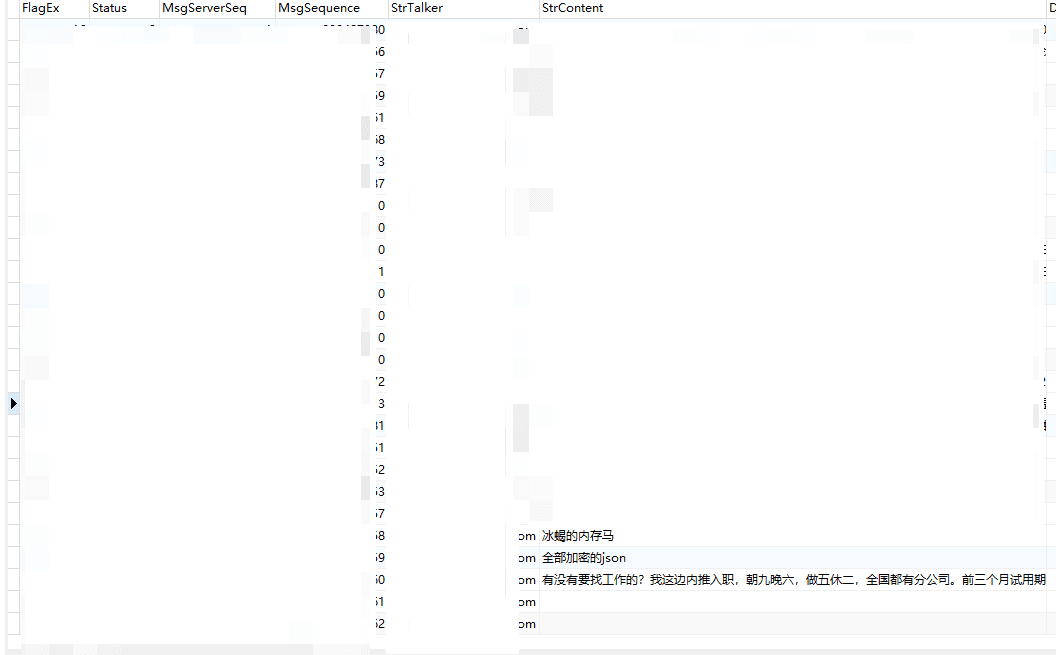
需要关注的字段有:
strtalker: 发送人微信 iD
StrContent:消息关键字
不知道 ID 怎么办 也很简单 全局搜索你曾经发送过的聊天记录,找到后筛选该值的所有匹配,
然后使用转储即可,我这里建议转储到 xlsx 表格里面。
到表格里面就更简单了,筛选出 StrContent 那一行到 TXT 里面,去除所有的字符和英文即可(并不严谨)
我是用了 python 处理了表格,参考代码如下:
import pandas as pd
import re
# 读取表格数据
df = pd.read_excel('cy.xlsx', sheet_name='Sheet1')
# 定义函数去除非中文字符
def remove_non_chinese(text):
pattern = re.compile(r'[^\u4e00-\u9fa5]') # 匹配非中文字符的正则表达式
return re.sub(pattern, '', str(text)) # 使用正则表达式替换非中文字符为空字符串
# 应用函数去除非中文字符
df['yue'] = df['yue'].apply(remove_non_chinese) # 将'column_name'替换为你要处理的列名
# 保存处理后的表格数据到新的Excel文件
df.to_excel('processed_file.xlsx', index=False) # 将'processed_file.xlsx'替换为你想要保存的文件名
print("处理后的表格数据已保存到 processed_file.xlsx 文件中。")
处理后的结果大概是这样的,比如我的聊天记录:
统计词频并分词#
分词需要用到中文停词表,我这里使用的哈工大的停词表
该项目地址如下:https://github.com/goto456/stopwords/blob/master/hit_stopwords.txt
提供一个分词代码:
import pandas as pd
import nltk
from nltk.tokenize import word_tokenize
from collections import Counter
# 读取文档数据
df = pd.read_excel('processed_file.xlsx', sheet_name='Sheet1')
# 去除无效的空行数据
df = df.dropna(subset=['yue']) # 将'column_name'替换为你要处理的列名
# 获取文档内容
documents = df['yue'].tolist() # 将'column_name'替换为你要处理的列名
# 加载中文停用词表
with open('hit_stopwords.txt', 'r', encoding='utf-8') as file:
stop_words = [line.strip() for line in file]
# 分词和去除停用词
tokenized_documents = [word_tokenize(doc) for doc in documents]
filtered_documents = [[word for word in doc if word not in stop_words] for doc in tokenized_documents]
# 计算词频
word_frequencies = Counter([word for doc in filtered_documents for word in doc])
# 创建词频DataFrame
df_word_freq = pd.DataFrame(list(word_frequencies.items()), columns=['词语', '词频'])
# 按词频降序排序
df_word_freq = df_word_freq.sort_values(by='词频', ascending=False)
# 保存结果到新的Excel文件
df_word_freq.to_excel('word_frequencies.xlsx', index=False)
print("词频结果已保存到 word_frequencies.xlsx 文件中。")
结果如下:
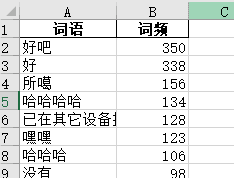
哈哈哈哈,还挺快乐的。
生成词云#
网上有很多项目可以生成词云,但是我找来找去没找到合适的,适合中文的,用了一个在线的服务,感兴趣的可以自行斟酌使用在线服务,如果有好的词云分析的可以留言推荐给我。
大概内容如下:

说明我们之间聊天真的很有意思,每天都是哈哈哈(bushi。
End#
再次感谢文章提到的所有作者和参考代码。
祝大家生活愉快,每天有爱。